

前回はYoomを使ったkintoneとChatGPT連携について書きました。
その後もChatGPTに関するブログはほぼ毎日のように見かけますが、今回はもう少し実務的な連携としてZoom会議の録音データをkintoneにアップロードし、chatGPTを連携させて音声から議事録を作成して管理する方法をご紹介したいと思います。
イメージはこんな感じです。
kintoneの議事録アプリにZoomで出力された音声ファイルを登録して保存をするとその音声ファイルからテキストデータを抽出し、抽出したテキストを元にChatGPT APIで議事録にして、結果をkintoneの議事録アプリに戻します。
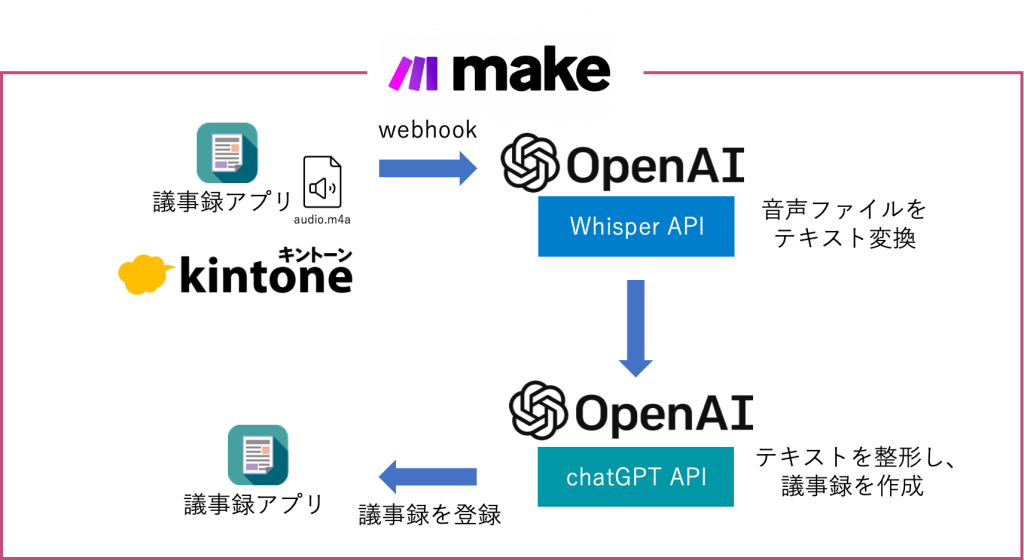
前回はYoomを使いましたが今回はiPaaSとしてmakeを使ってここでもノーコードで連携をさせてみたいと思います。
弊社では初回開発無料の定額39万円でkintoneアプリを開発する定額型開発サービス「システム39」を提供しております。kintoneの導入やアプリ開発でお困りの方は、お気軽にご相談ください。
*Webでの打ち合わせも可能です。
kintoneで議事録アプリを作成
まずはkintoneで議事録アプリを作ります。
アプリ構成はこんな感じ。
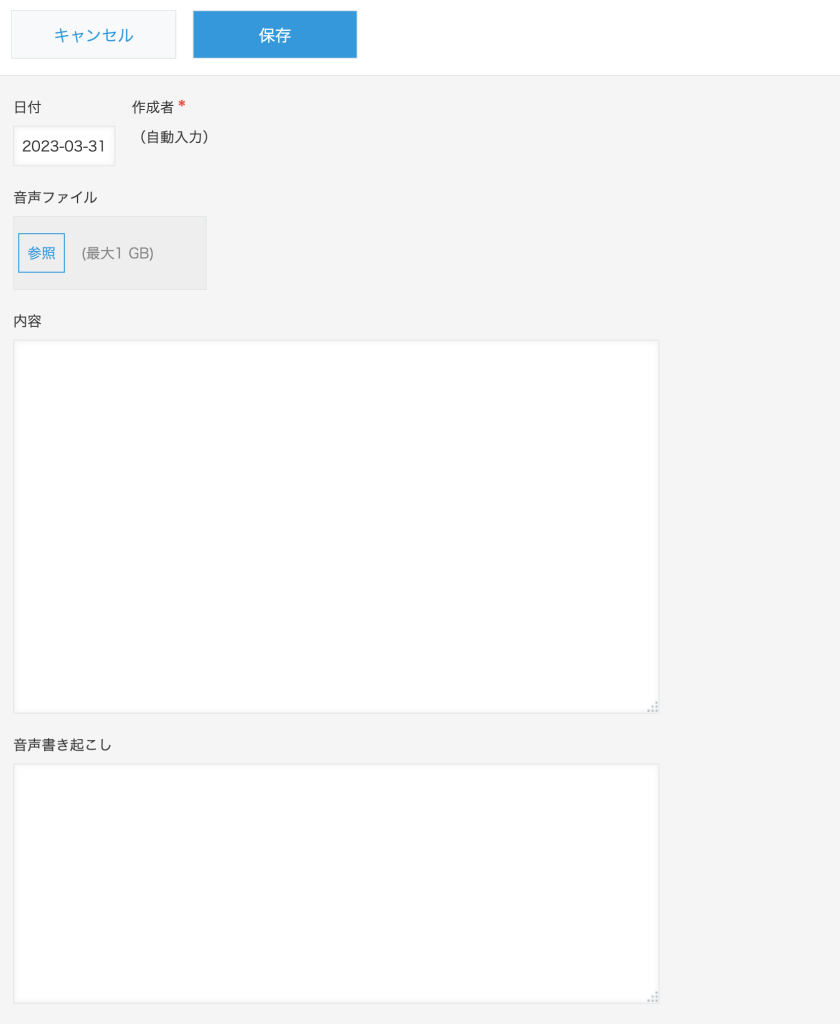
ZoomでWeb会議を行う際にレコーディングを行うと動画ファイルの他にチャットの履歴や音声だけのファイルも出力をしてくれますので、その音声ファイルを保存するための音声ファイルフィールドを設けます。
それ以外に音声ファイルをテキスト変換したものを登録する「音声書き起こし」フィールドと議事録としてまとめられたものを登録する「内容」フィールドを作ります。
Zoomの音声ファイルをWhisperAPIで変換
OpenAIでは音声ファイルをテキスト変換してくれるWhisper APIというのを提供していますので、まずは音声ファイルをWhisperAPIでテキスト変換します。
kintoneからmakeに音声ファイルを渡すためにkintoneのwebhookを使います。kintoneの添付ファイルを取得するためにはwebhookで送られてきたJSON内にあるファイルキーを使ってファイルダウンロードのAPIを使って取得します。
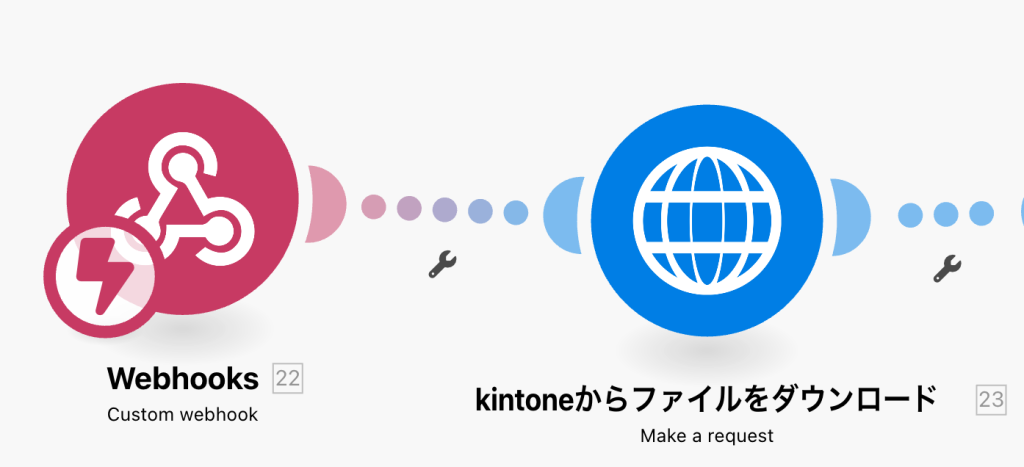
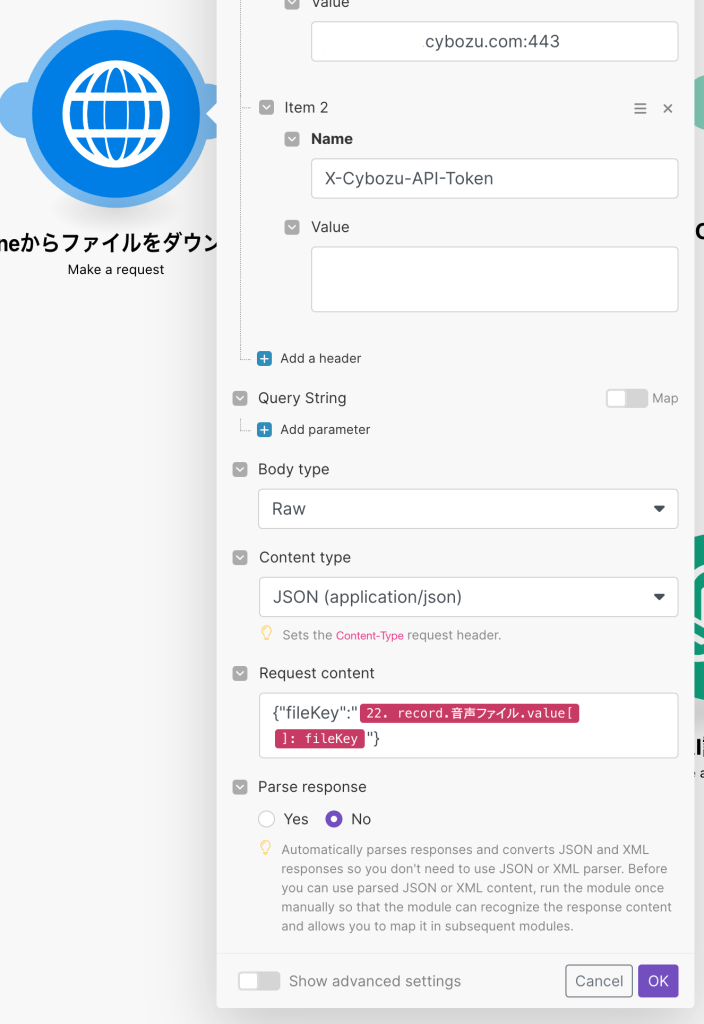
ファイルダウンロードのAPIについてはこちら。
https://cybozu.dev/ja/kintone/docs/rest-api/files/download-file/
次に取得したファイルをHTTPモジュールを使ってOpenAIのWhisper APIに投げます。
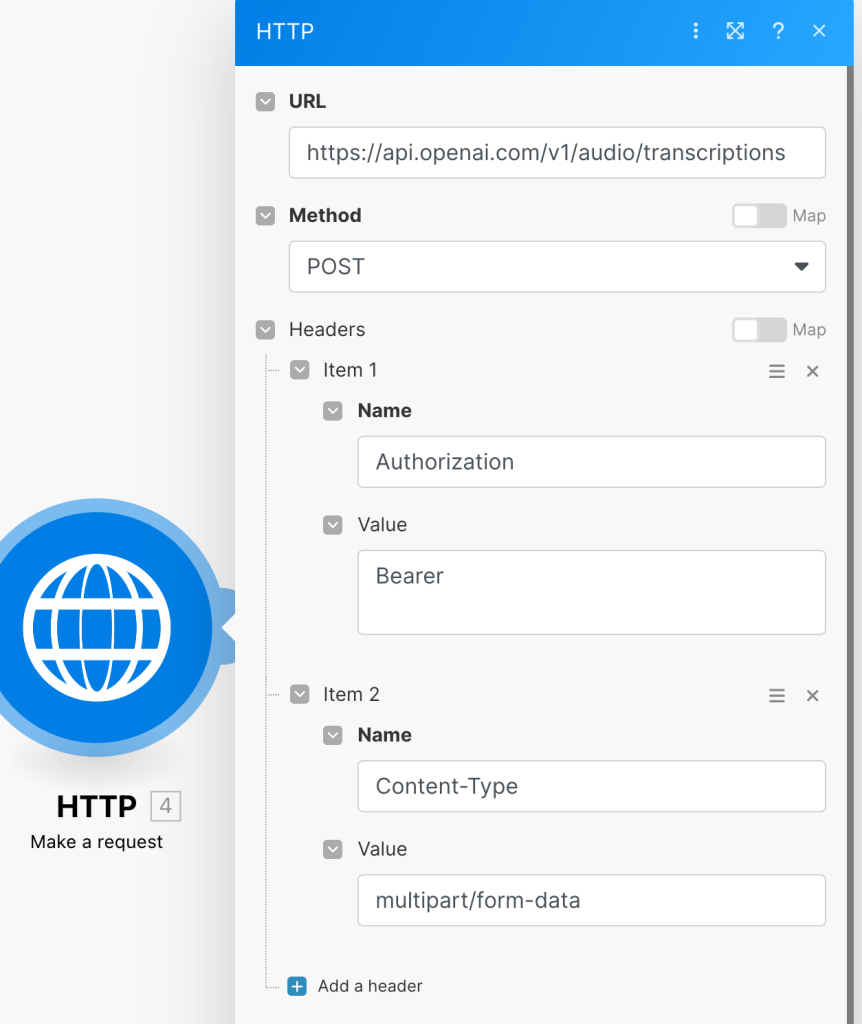
URLは「https://api.openai.com/v1/audio/transcriptions」でHeaderにOpenAPIで取得したAPIキーをAuthorizationのValueとして Bearerの後に記載します。
Content-Typeは「multipart/form-data」としてください。
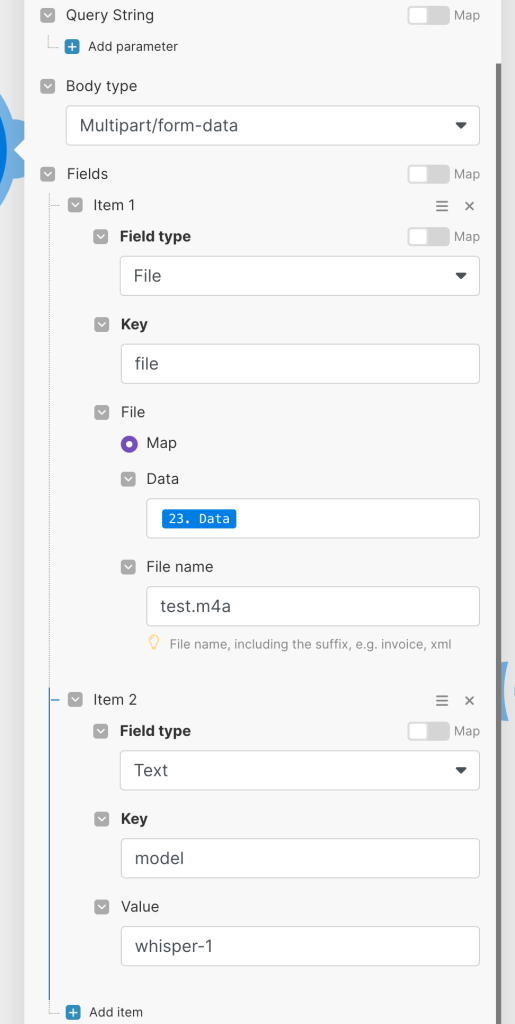
FieldsにはField typeとして「File」を選択し、Keyには「file」と入力してFileのところで前のモジュールで取得した音声ファイルのデータをData欄に指定してFile nameにファイル名を入れます。このとき拡張子は必ずWhisper APIで対応している拡張子にしてください。Zoomではm4a形式で取得できるのでここでは、test.m4aとしています。
もうひとつのItemにはWhisperAPIのモデルを指定します。Field typeは「Text」とし、Keyには「model」、Valueには「whisper-1」と入れます。
これで音声ファイルからテキスト抽出ができてしまいます。拍子抜けするほど簡単。
音声から抽出したテキストから議事録を作成
これで音声からテキストファイルを抽出できたので早速、議事録を作りたいところですが、抽出したテキストファイルは会話をそのままテキストに起こしてるだけなのでこんな感じででてきます(笑)
「同じでいいと思う じゃあここに一応追記するっていう感じに一旦して すぐ対応するかどうかを小林さん含めて アップデートをどれにするかって考えるときに考えると思うので 概要ページに機材が付属しているんじゃないかと 概要ページには書いてある まだ終わってないんだよねここ もうやってるんだっけ 今確認待ち 終わってないです まだ手付けてないところだよね 手付けるときにそこ書いてもらえればいいと思う 機能のところで これはバグで採用になってるので 一旦押します 採用でいいんですかね 対応考える そうですね 逆に逆に逆に 逆に逆に 逆に逆に 逆に逆に 逆に逆に 逆に逆に 逆に逆に 逆に 逆に 逆に 逆に 逆に 逆に 逆に 逆に 逆に 逆に 逆に」
このままでも議事録は作れちゃうのですが、せっかくテキストに抽出できたのでこの会話自体を整形して、やり取り自体もkintoneの議事録アプリに入れて整形したデータを元に議事録を作りたいと思います。
makeにはOpenAIのChatGPT用のモジュールが用意されているのでそれを使っていきます。
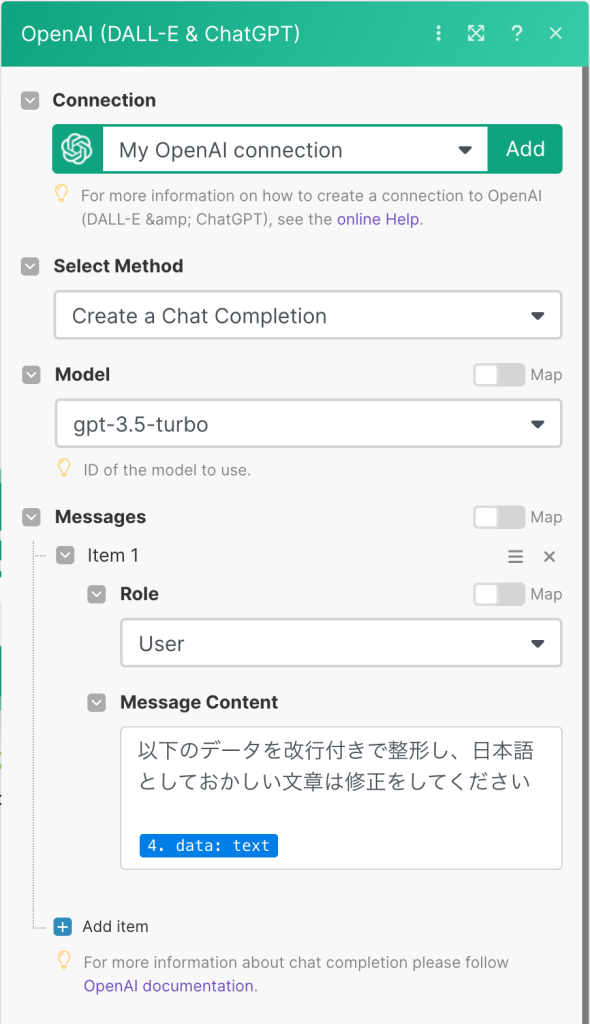
まずは音声から抽出したテキストファイルを整形します。
Methodは「Create a Chat Completion」を選び、Modelには「gpt-3.5-turbo」を選びます。(gpt-4早くこい)
Roleは「User」を指定して、Message Contentに「以下のデータを改行付きで整形して、日本語としておかしな文章は修正してください」という指示のものとWhisper APIで取得したテキストデータを指定します。
ここで生成されたデータは後でkintoneの議事録アプリに登録します。
次にもう一つChat GPTモジュールを作って、整形された会話データから議事録を作ります。
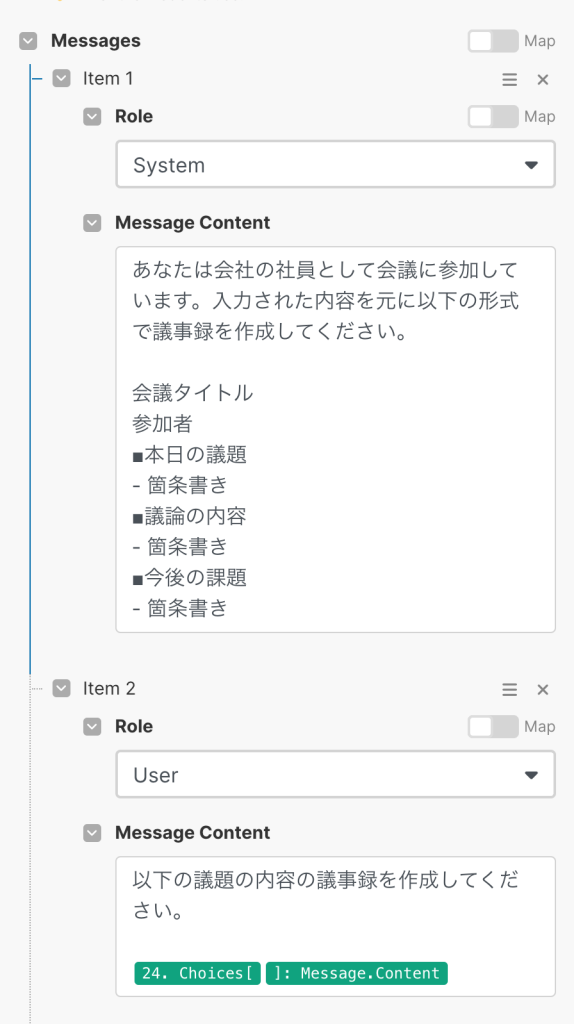
今度はSystemロールを使ってChat-GPTに役割を指定します。今回は会議に参加している社員として会議タイトルや参加者、本日の議題と内容、今後の課題についてまとめる役割として動いてもらうよう支持しました。
そして、もう一つはUserロールにして「以下の議題の内容を議事録として作成してください。」と支持し、整形された会話データを指定します。
後は作成されたテキストデータをkintoneの議事録アプリに更新します。
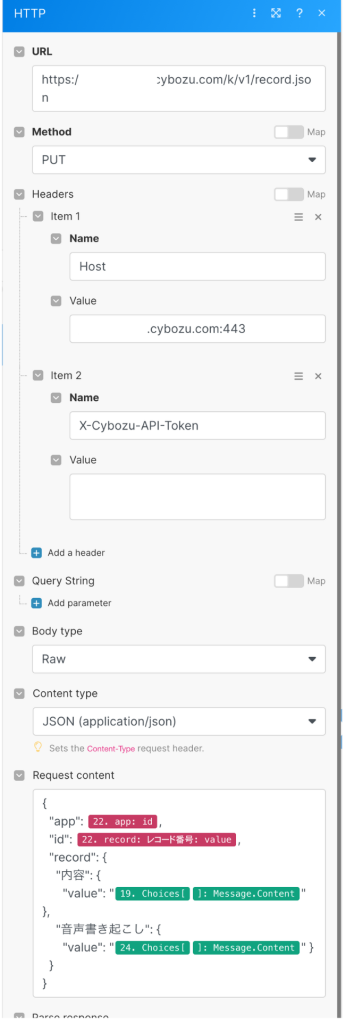
kintone用のモジュールもありますが今回はHTTPモジュールを使ってAPIを直接叩きました。
必要なヘッダー情報を指定してRequest contentにはWebhookで取得した議事録アプリのアプリIDとレコード番号を指定し、内容フィールドには議事録データ、音声書き起こしフィールドには整形された会話データを指定します。
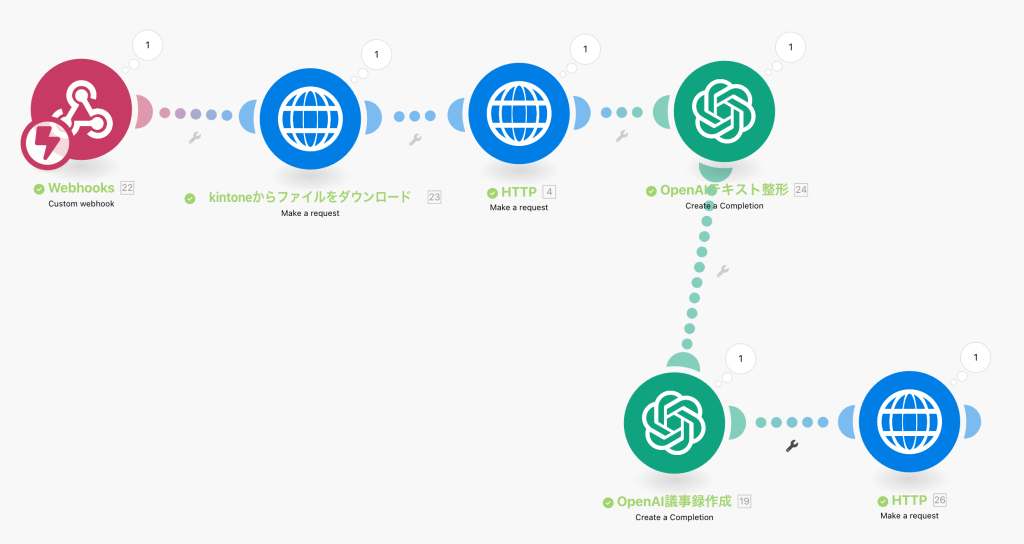
全体のフローはこんな感じになります。
kintoneに音声ファイルをアップロードしてみる
これでmakeの設定は完了したのでmakeで作ったフローを実行状態にしてからkintoneに実際に音声ファイルをアップロードしてみます。
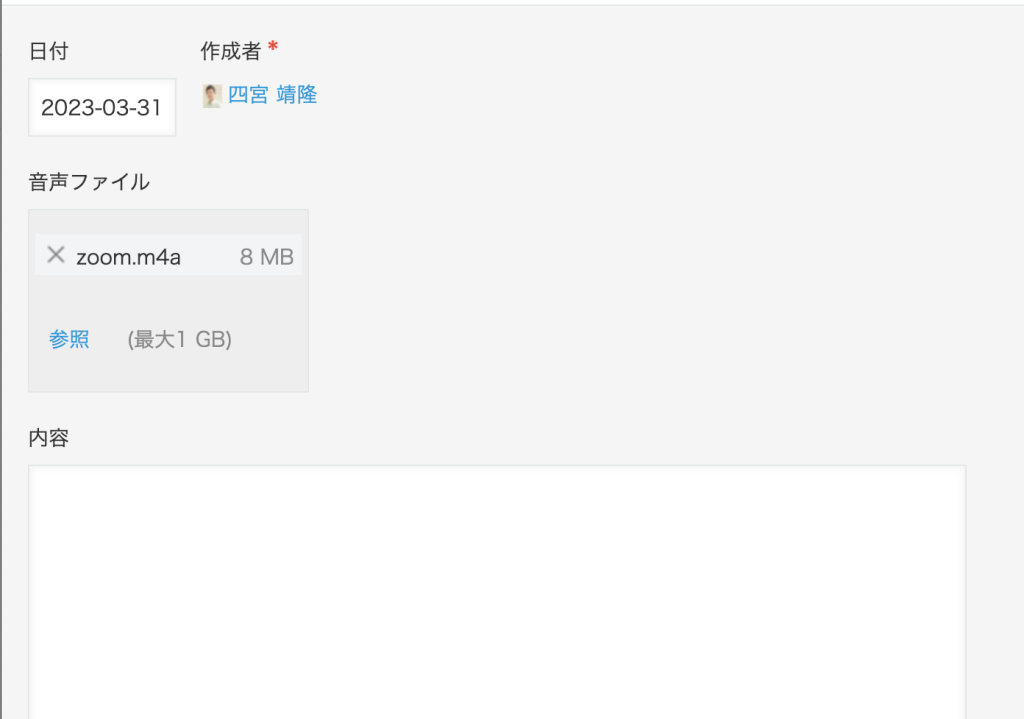
音声ファイルフィールドにZoomでレコーディングした「zoom.m4a」ファイルをアップして保存します。
保存のタイミングでwebhookを使ってmakeにデータが渡りますので、kintoneの画面上で1〜2分待ってからブラウザをリロードすると・・・
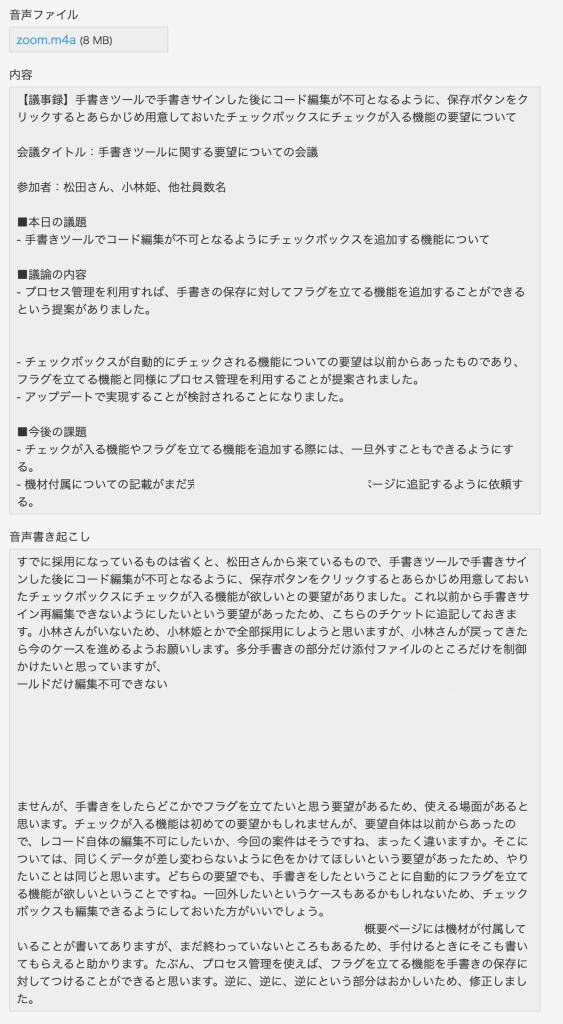
このような感じでまとめられた議事録と音声書き起こしのデータが登録されてきました。
今回音声データとして社内のプラグイン開発に関する打ち合わせデータを実際に使ってみたのですが、もちろんいくつか修正があるものの全体的に内容は把握できる議事録が出来上がりました。(小林さんという名前が何回実行しても「小林姫」になりました。)
後はこれを微調整するだけで議事録として成立するレベルのもの完成します。(実データなので一部マスクしてますw)
ブラウザ版のChatGPTとは違ってOpenAIのAPI経由を使う場合、データは基本的に学習用途には使われない規約となっていますので、利用範囲を考えれば実務用途として活用できるケースは色々あるのではないかと思います。
企業のセキュリティポリシーを十分考慮しながら有効に利用できる方法については今後も色々と模索をしていき、また良い活用例ができましたらブログの方にアップしていきたいと思います。
弊社では初回開発無料の定額39万円でkintoneアプリを開発する定額型開発サービス「システム39」を提供しております。kintoneの導入やアプリ開発でお困りの方は、お気軽にご相談ください。
*Webでの打ち合わせも可能です。


